
The Ultimate Guide to LLM Benchmarks
As the adoption of Large Language Models (LLMs) continues to transform industries, evaluating their performance is critical. LLM benchmarks play a vital role in measuring the capabilities, accuracy, and versatility of these models across a variety of tasks. From natural language understanding to problem-solving and coding, benchmarks help us understand how LLMs can meet real-world challenges.
In this blog, we’ll explore the top benchmarks that define the performance of LLMs, categorized into Natural Language Processing, General Knowledge, Problem Solving, and Coding. Whether you’re an AI researcher, developer, or enthusiast, this guide will help you navigate the world of LLM evaluation.
1. Natural Language Processing (NLP) Benchmarks
Natural Language Processing is the backbone of LLMs, enabling them to interpret, analyze, and generate human-like text. Here are some of the most significant NLP benchmarks:
- GLUE (General Language Understanding Evaluation):
This benchmark tests core NLP tasks such as paraphrasing, sentiment analysis, and inference. Models are scored on their ability to detect paraphrase similarity and perform sentiment analysis accurately. GLUE has become a standard for evaluating the linguistic understanding of LLMs. - HellaSwag:
Designed to assess a model’s ability to predict the next sequence of events, HellaSwag uses adversarial filtering to ensure tasks are challenging. It measures sentence completion accuracy, making it a go-to benchmark for evaluating contextual reasoning. - MultiNLI (Multi-Genre Natural Language Inference):
MultiNLI pushes models to understand inference across multiple genres. It evaluates the ability to assign correct labels to sentence pairs, a critical skill for tasks like sentiment analysis and document summarization. - Natural Questions:
This benchmark tests how well LLMs can extract answers from large datasets such as Wikipedia. It evaluates the correctness of both short and long answers, making it highly relevant for search engines and question-answering systems. - QuAC (Question Answering in Context):
A unique benchmark designed to simulate interactive student-teacher dialogue, QuAC measures a model’s contextual understanding during open-ended conversations. - SuperGLUE (Super General Language Understanding Evaluation):
A successor to GLUE, SuperGLUE tests models on advanced NLP tasks and aggregates scores across diverse tasks, such as reasoning, coreference resolution, and textual entailment. - TriviaQA:
This benchmark focuses on testing a model’s ability to answer challenging trivia questions based on reading comprehension. - WinoGrande:
Known for resolving pronoun ambiguities in complex sentences, WinoGrande evaluates how well a model can understand contextual relationships.

2. General Knowledge Benchmarks
General knowledge benchmarks test how well LLMs can reason, recall information, and provide accurate answers across a variety of subjects:
- ARC (AI2 Reasoning Challenge):
This benchmark requires models to answer science-based multiple-choice questions. It’s a robust test for reasoning and factual knowledge. - MMLU (Massive Multitask Language Understanding):
MMLU evaluates knowledge across 57 different subjects, from history to biology. Its diverse scope makes it a comprehensive benchmark for academic and general knowledge assessment. - OpenBookQA:
Mimicking open-book science exams, this benchmark tests a model’s ability to answer questions using provided facts. It focuses on reasoning based on available data. - PIQA (Physical Interaction Question Answering):
PIQA is designed to test a model’s understanding of physical interactions and scenarios, ensuring practical reasoning. - SciQ:
Focused on science, particularly physics, chemistry, and biology, SciQ challenges LLMs to deliver correct multiple-choice answers in a structured format. - TruthfulQA:
A unique benchmark that checks the truthfulness of LLM responses, ensuring that models do not perpetuate misconceptions or falsehoods.
Also Read – The Ultimate LLM Leaderboard: Comparing Top Language Models
3. Problem-Solving Benchmarks
Problem-solving is a critical domain where LLMs showcase their ability to reason, interpret, and execute complex tasks. These benchmarks assess their logical and mathematical capabilities:
- AGIEval (Artificial General Intelligence Evaluation):
AGIEval is designed to test reasoning skills with SAT-style questions. It measures how well an LLM can solve abstract and logical problems, making it an excellent indicator of advanced reasoning-based accuracy. - BIGBench (Beyond the Imitation Game Benchmark):
BIGBench is one of the most extensive benchmarks, encompassing over 204 tasks across multiple domains. It evaluates multistep reasoning and domain-specific task completion, making it ideal for testing the generalization capabilities of LLMs. - BoolQ (Boolean Question Answering):
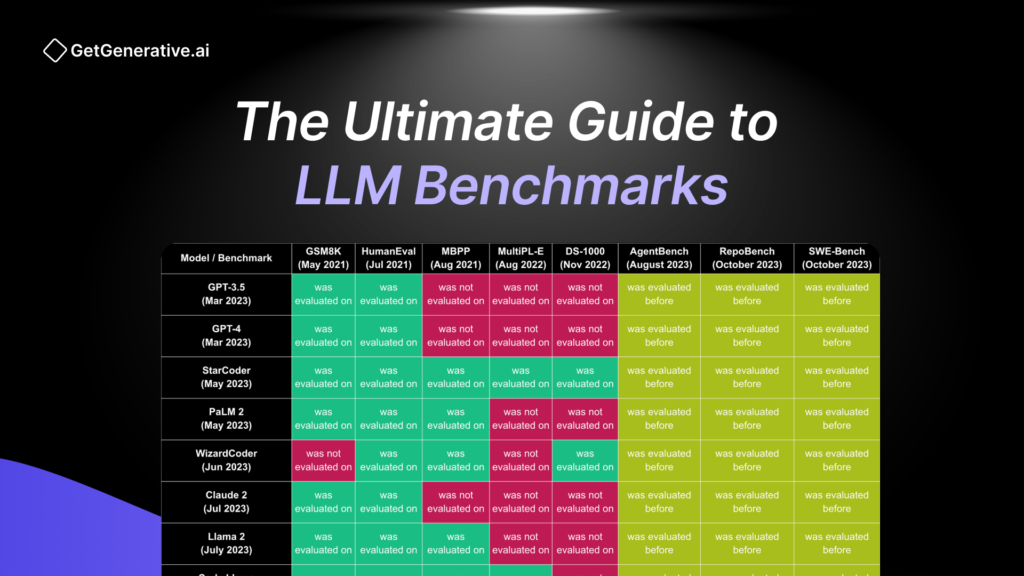
BoolQ tests the ability of models to answer yes/no questions sourced from platforms like Google and Wikipedia. Its focus on binary decision-making highlights a model’s contextual comprehension skills. - GSM8K (Grade School Math 8K):
GSM8K evaluates how well LLMs solve multi-step mathematical problems. This benchmark is critical for assessing numerical reasoning and arithmetic capabilities.
4. Coding Benchmarks
The rise of LLMs in software development has brought coding benchmarks into the spotlight. These benchmarks test how effectively models can generate, interpret, and debug code.
- CodeXGLUE:
This benchmark evaluates LLMs in various coding tasks, such as translating text into code and vice versa. Success is measured by performance across tasks like code completion and documentation generation. - HumanEval:
HumanEval measures the functional correctness of generated code using unit tests. It provides an excellent standard for assessing how accurately a model can produce working solutions. - MBPP (Mostly Basic Python Programming):
Designed for entry-level coding tasks, MBPP evaluates an LLM’s ability to solve basic Python programming challenges. This benchmark is a key indicator of a model’s coding proficiency for beginners.
The Importance of Benchmarks in AI Development
Benchmarks serve as the compass for the rapid development of large language models. They:
- Help identify strengths and weaknesses in LLMs.
- Set performance standards that guide innovation in AI research.
- Build trust among users by ensuring reliability, accuracy, and truthfulness in real-world applications.
As LLMs grow in complexity and adoption, benchmarks are becoming increasingly sophisticated, offering new ways to measure and improve AI performance.
Also Read – Your Go-To Guide: The Ultimate AI LangChain Cheatsheet
Final Thoughts
The future of LLMs lies in continuous improvement, and benchmarks are a cornerstone of this progress. Whether it’s natural language understanding, problem-solving, or coding, these benchmarks ensure that LLMs are aligned with human expectations and use cases. They’re not just about competition—they’re about collaboration, pushing the boundaries of what AI can achieve.
Supercharge your Salesforce implementation with GetGenerative.ai – AI-powered Workspaces and Agents for seamless lifecycle management, from Pre-Sales to Go-Live. Try it now!

